
你瞭解卡片盒筆記(ZK, Zettelkasten)之後,有持續使用建立個人知識庫嗎?或是覺得真麻煩或根本聽不懂放棄了呢?卡片盒筆記的過程複雜又難懂?但你可以試試看用 AI 專用的 Embeddings Model 讓它自動化!
最近 Google 旗下的 NotebookLM 非常紅,我都想立刻全面改用了,但 NotebookLM 只能 import 有限內容,比較適合把指定幾個文件整理完寫篇小文章或簡報,如果像第二大腦 ZK 那樣每天記錄一生累積萬篇筆記,或你打算叫它把你一屋子的書整合協助寫博士論文,這是它做不到的。
像 NotebookLM 這麼聰明的筆記本能不能跟我的 ZK 結合起來呢?我不禁這麼思考。
本文目錄
卡片盒筆記的痛點–反思
ZK 是德國社會學家尼可拉斯・盧曼(Niklas Luhmann)在 1954 年左右發明的,融合了科層組織(Hierarchy)、德國人最擅長的文件管理(我猜跟他公務員背景有關),如果你經歷過 ISO 標準,就知道德國人花多少力氣鄭重地管理文件了。但盧曼最強的是超時代引入「超連結」觀念,讓你能從樹狀目錄筆記之間建立捷徑。
樹狀目錄就像你去 IKEA 把一層樓隔成繞來繞去的路徑,但如果你內行就知道有捷徑,一道門穿過去可以從兒童區穿到餐廳,就是超連結了。
我猜你接觸「超連結」應該是從網站吧?那是提姆・柏內茲・李(Tim Berners Lee)在 1989 發明的,從 1954 ~ 1989 間的 30 幾個沒有網路的年頭,盧曼可能是全世界少數每天使用「超連結」的人,從這個角度想,他確實很前衛。
ZK 的講解請參考我之前一系列文章,就不重複了。
ZK 是「知識庫」而不只是「筆記軟體」,就是因為要進行「後處理」把零碎的資訊整合為知識,過程是:
- 記錄下來:隨手把感想筆記寫在軟體中;
- 提煉標籤:從筆記中提煉出標籤,就是跟其他筆記相似處;
- 產生連結:文章可能引用別的筆記或被引用;
- 發展知識:從片段內容發展成完整的思想。
多數人做了幾次就放棄了吧?寫完還要整理太麻煩了,沒時間啦!但不進行後處理,寫在 ZK 軟體或是隨便一張紙效果是差不多的。
就算有特別花時間去整理的人如我,受限於魯鈍的大腦,能串接都是最近的主題,幾年前的筆記根本就忘了,想不起來有它要怎麼串連?
1954 發明至今 70 年了,知道 ZK 的人不多,能善用的人更少,證明「後處理」太難,流行不起來!
Embeddings Model 是怎麼分類的?
人類用標籤、連結來後處理幫筆記歸類,而聰明到讓我們掉下巴的 ChatGPT 一類大語言模型則是用「Embeddings Model」來後處理歸類知識,你可以把它當作「AI 的 ZK」,它閱讀文章後,依照語義把文章歸檔到 1536 維的向量空間……(咳咳!這是啥?)很難懂對吧?雖然不準確,讓我們用人類的思維,把它類比為它把文章貼了 1536 個標籤!
不止如此,人類只能做到「有貼標籤」和「沒貼標籤」兩類,AI 卻可在 1536 個標籤上每個都「加權」(可以把它想成「刻度」)
| 分類 | 人類 | AI |
|---|---|---|
| 狗 | #寵物 | #寵物 = 1.00 |
| 水豚 | #寵物(雖然多是在動物園) | #寵物 = 0.30 |
| 獅子 | #野獸(大概只有戰鬥民族會養,太少了) | #寵物 = 0.01 |
- 人的標籤,如果搜尋「寵物」會列出:狗、水豚,有人會覺得「水豚能算寵物嗎?」;
- AI 的標籤,搜需「寵物」列出:狗 > 水豚 > 獅子,你會看出來有程度的差異,是比較精細的標籤。
假設有幾篇文章「學習是個人成長的關鍵」、「運動促進身心健康」、「閱讀和反思幫助理解新知識」,被處理成下面的 6 維標籤,每一維都有向量距離(刻度):
[0.193, -0.324, 0.567, -0.765, 0.434, -0.231]
(這個例子只有 6 維,OpenAI Embeddings Model 有 1536 維,是這行的 256 倍)當你 prompt 有「成長」,這三篇文章都會被搜到,就算後兩者根本沒有「成長」這兩個字,但是從語義可以推測,所以它是很聰明的搜尋,字不對還是能搜到。
我連 100 個標籤都記不住,別說每個標籤都還有小數後 3 位的刻度,那不就變成幾萬個標籤嗎?可是,這數量對 AI 來說完全不是問題。
AI 處理後的資料就變成一個「Embeddings」,要存進專用的「Embeddings Database」(有人翻「向量資料庫」),當你詢問 AI 時,它也對你的問句後處理,所以你的 prompt 也變成 Embeddings,兩相比對就知道哪些資料跟問句最相似,快速取出相關資料。
這麼聰明,解決了人類不擅長分類資料的問題,不管你覺得太麻煩懶得後處理,還是像我記性不好只記得最近所學,有了 Embeddings Model,可以把後處理全交給它了。
Embeddings Model 如何整合筆記?
既然 Embeddings model 這麼好,筆記軟體有嗎?有!但請記得那些動作都是生成式 AI 做的,任何軟體都只是代理這些 LLM,你要自己花錢向 OpenAI、Claude… 買點數才能用。
ZK 軟體內的解法
- Obsidian:Semantic Search for Obsidian、Zettelkasten LLM Tools、Obsidian AI 等;
- Logseq:GPT-3 OpenAI、Logseq AI Auto Tags 等;
- RemNote:期待中。
最近軟體都整合了 AI,我看到幾個寫 AI 插件的方向,找錯了也沒用:
- 下 prompt 產生文字圖片的插件:這不是你要找的;
- 幫你總結筆記的插件:對,這就是你要的,關鍵詞多是:semantic search, summarize…;
- 其他功能的插件:例如打字打一半就自動幫你把字打完,這是用類似技術,但對我們現在講到的用途無益。
Obsidian 有最大的社群、最高的搜尋量,所以流行插件數量很大,相較之下 Logseq 這個新軟體就小很多,而 RemNote 是商業軟體,開發多由企業做,更小,當享受 RemNote 很好的整合時,不由羨慕擁有大社群的人多勢衆啊!
但老實說,如果你要從「手工知識庫」轉移到「AI 知識庫」,這些插件都不完整,你想啊!Obsidian 和 Logseq 都在自己電腦上運行,把檔案存成 md(markdown)格式,但 embeddings 要存在「Embeddings DB」中,少說也要存成電腦比較能讀的 JSON 格式,那這插件到底存到哪裏去了?
很簡單,它把文字辨識完後,把這些儲存在它自家伺服器,所以你的筆記不再是你的。
純 AI 解法
這方法完整但不簡單,筆記和 Embeddings 都存在自己的資料庫,再產生自己的聊天機器人,就像熟讀你一言一行的小粉絲,問什麼都能依據你的筆記回答,全部私有當然保密。
除非 ChatGPT 把你的筆記拿去做為訓練材料,你的資料永遠是你的
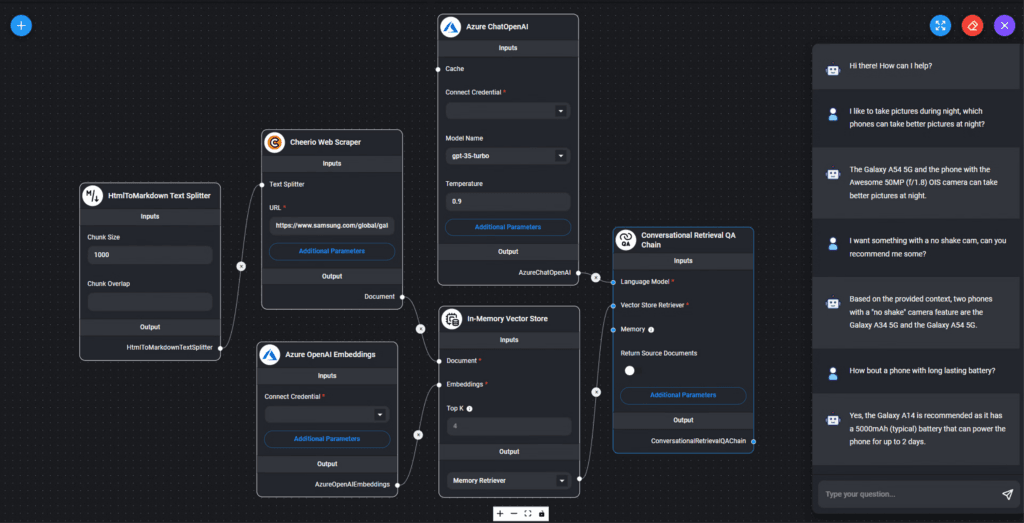
要把內容交給 Embeddings model 來「閱讀」,再存入一個資料庫,這需要一套流程,總不能每一篇你都等它讀完再自己去手工儲存,現在有一些 「Low Code AI App 建立工具」,可以用拖拖拉拉不用寫程式就可以建立跟 AI 問答的流程。例如:
- 輸入筆記
- 用 Embeddings Model(每家都有一套)閱讀採集特徵
- 把原筆記和特徵存到向量資料庫(最親民的是 Supabase,高手可考慮 Pinecone、Weaviate)
- 建立聊天機器人。LLM 會先讀筆記後回覆,而不會胡扯。
Low Code AI App 建立工具有哪些?國外的如 Flowise 或 Dify,台灣團隊 Simpleinfo 也提供了比較早期的工具,這樣的代理工具應該會越來越多,如果我又知道了就來此更新。
雖然都是開源軟體,用 Docker 自己安裝免費,但安裝多個應用有難度,如果對技術研究不感興趣,可以付費買線上版,但所費不貲,以 Flowise USD$35/月 + Supabase USD$25/月 = USD$60/月,還沒算付給 LLM 的錢,看用量和買了哪一家,價格各有不同。
Embeddings 與標籤的 Mapping
AI 模型會建立 1536 個特徵(標籤),那我還需要去貼標籤嗎?
人類看不懂 AI 如何分類的,但這是你的筆記啊!你至少要能掌握,有一天沒有 AI 也能找到分類。
不過我分成 100 個標籤,而 AI 分成 1536 個標籤,不就亂了嗎?
為了搭配 100 個人類可讀標籤,AI 要先為標籤「降維」或「聚類」,深度學習會把一堆亂七八糟資料,找出誰跟誰比較相似,然後把它們分成一堆一堆,這一群相似的建議共用一個標籤。
你也可以把人的標籤當作教材,例如「珍珠奶茶」和「蚵仔煎」,AI 都分到「#餐飲」,但我卻分類到「#臺灣夜市小吃」,聰明的 AI 看見,接下來「麪線」、「碗粿」會自動分到正確的位置。
所以把 AI 能讀的 Embeddings 和人類能讀的標籤互相 mapping,就像是人機互相理解的界面。
這裡的功能還不存在,甚至它可以建議要貼什麼標籤,這可能要寫程式達成。
自動化對學習是幫助還是傷害?
對我來說,筆記有幾個重要功能,第一層是學習手段,第二層當作「第二大腦」方便查詢,第三層藉着整理發現跨科目的連結或靈感。
| 層級 | 用途 | 原做法 | 調整做法 |
|---|---|---|---|
| 第一層 | 筆記幫助學習 | 手寫筆記、整理筆記,重複接觸 | 保持不變 |
| 第二層 | 筆記是快速查詢的個人知識庫 | 串連各篇筆記、增加標籤 | 用 embeddings model |
| 第三層 | 從筆記跨科目發現靈感 | 整理不同學門筆記,刺激大腦產生創意 | 與自有 AI 聊天機器人深談產生創意 |
從 ChatGPT 問世第一天就重度使用 LLM,近兩年雖然在很多地方使用它,但自始至終,寫筆記堅持是我自己的事,原因很簡單,整理筆記第一層功能,它是個學習手段,類似小時候地理課用描圖紙描地圖填地名,這些「做功」讓知識進入長期記憶。
筆記的第二層功能是可以建立「第二大腦」,從這角度,最重要功能是「快速找到需要的筆記」,我的標籤檢索系統比不上 AI,應該交給它。
只要筆記只記錄思考心得(而非文摘),則 AI 知識庫裡都是我的思想,那就是「我的」第二大腦。比較另一種狀況,有個人的筆記裡是把網上、書上別人寫的內容 copy & paste 進去,那 AI 學到的不是他,而是別人的認知,如果是大衆媒體,那更是個普遍認知,我認為,如果筆記只是這種用法,真不用花那麼多力氣建立知識庫,ChatGPT 讀的書更多,更是普遍認知啊!
筆記終極應用是第三層,跨科目整理或閱讀筆記時,你會被刺激、觸發靈感、創意,或是發現在單一學科無法發現的巧思,但把跨科目串接的工作交給 AI,就失去發現跨界靈感的機會了,比較困擾。
可能的方法,一、你還是繼續用傳統方式整理筆記順便發現彼此關係;二、藉由與 AI 互動發現跨科目的靈感。
我發現,如果 AI 回答答案時,別想「這答案太好了」就相信而被它一次搞定,反之,如果一邊聊、一邊思考,就能找茬,發現它不完善之處,一直追問,它只能一直回答,這種深聊其實還滿能發現新點子的!希望這些方式可以強化筆記的第三層功能,成為靈感來源!